
Gradient descent finds parametric manifolds
A story of linear probe failures, successes of DAS, and a parametric manifold


*This post is currently a WIP
Introduction
Understanding how LLMs bind information to entities in their internal representations is an important goal in mechanistic interpretability. It’s a core capability which is required for the execution of most of the useful work that we use LLMs for. In recent years, progress has been made on this problem, with the discovery of the binding IDs. A binding ID is a piece of information that act as label corresponding to a particular entity in the prompt, and they are often found in the residual stream of tokens corresponding to properties of or state assigned to that particular entity. Since the discovery of binding IDs, it has been found that these are in fact ordering IDs (OIs). Ordering IDs form an incremental indexing system, assigned to entities based on the order that they appear in. For example, in the sentence: “Sam and Greg walked to Sam’s house”, Sam would be assigned the first OI, and Greg the second.
In Prakash et al 2025, causal interventions are used to pin down the flow of information inside Llama-3-70B-Instruct during tasks that require differentiating between different named individuals that appear in the prompt. While the experiments were designed primarily to investigate how LLMs track the beliefs of multiple individuals simultaneously, an interesting intermediate result in the paper proves that the model uses OIs. The results show that these OIs are used as “pointers” to individuals appearing in the prompt, which are dereferenced to retrieve other information relevant to the task.
This paper shows the most sophisticated OI using mechanism in an LLM I’ve seen, making it a good place to investigate the representation of OIs more deeply, in a realistic context. I train probes on two different parts of the model to find how OIs are represented, in two different parts of the mechanism. One set of probes finds an interpretable manifold, while the other does not. I do causal interventions which show that the first manifold is not causally relevant, while the second is somewhat implicated but not the whole story. I then introduce a gradient based method, a variant of Distributed Alignment Search (DAS) which finds a different subspace at both parts of the mechanism, that is both causally relevant and interpretable as a manifold. This gradient based method also finds a parametric manifold, whose curve changes shape depending on the number of individuals mentioned in the prompt. This parametric nature partly explains the probes’ inability to find that representation. My experiments were done on Qwen3-14B.
Prakash et al 2025
Prakash et al’s experiment uses 2 prompts, a donor and recipient. The recipient is a prompt explaining that 2 named individuals are working in a busy restaurant, and how they each fill a particular type of container with a different kind of liquid, followed by a question asking which liquid one of the individuals believes is in their container. The donor prompt is identical to the recipient, except that the order that people are first introduced in is swapped, the order of sentences pairing the individuals with their state is swapped, and the liquids in each prompt are unique. In this context, I call the first sentence the introduction sentence, and following sentences state assignment sentences.

The baseline result shows the LLM correctly answers the question in the recipient prompt, producing the token “Coffee”. In the intervention, the residual stream for the final token “:” in the recipient prompt is fully replaced with the residual stream from the donor prompt’s “:” token, in a specific layer range. The result is that the LLM’s answer to the question is now the liquid in the container owned by the other individual in the recipient prompt, Bob. Since the 2 prompts differ only in order, the model must be retrieving the answer using pointers that are assigned to names based on the order they appear in.

Dataset
Prakash et al, for the above experiment only uses prompts with 2 names, and alters the names, containers, and drinks, by pulling them randomly from a set, for a total of 80 variations. They also only test the configuration where the recipient prompts question asks about the second name. To investigate the OI representation more deeply, I want to be dealing with a wider range of OIs, and to do so, I constructed my own dataset generator based on the prompts used in Prakash et al, which in addition to randomizing names, containers and drinks, uses up to 6 names in a single prompt, and covers all combinations of donor and recipient index.
The inputs to this data generator are; the number of individuals / names in the prompt (n), from 2 to 6, and a target index, from 1 to n. The target index is the index of the individual who will be the target of the question. The intro sentence which introduces each name, is then generated. Next, a state assignment sentence for each name is generated from a simple template into which the chosen name, container, and liquid are substituted into. Then, the question is generated, using a template that is filled in using the name and container corresponding to the target index. The order of names presented in the introduction sentence, and the order of state assignment sentences are the same.
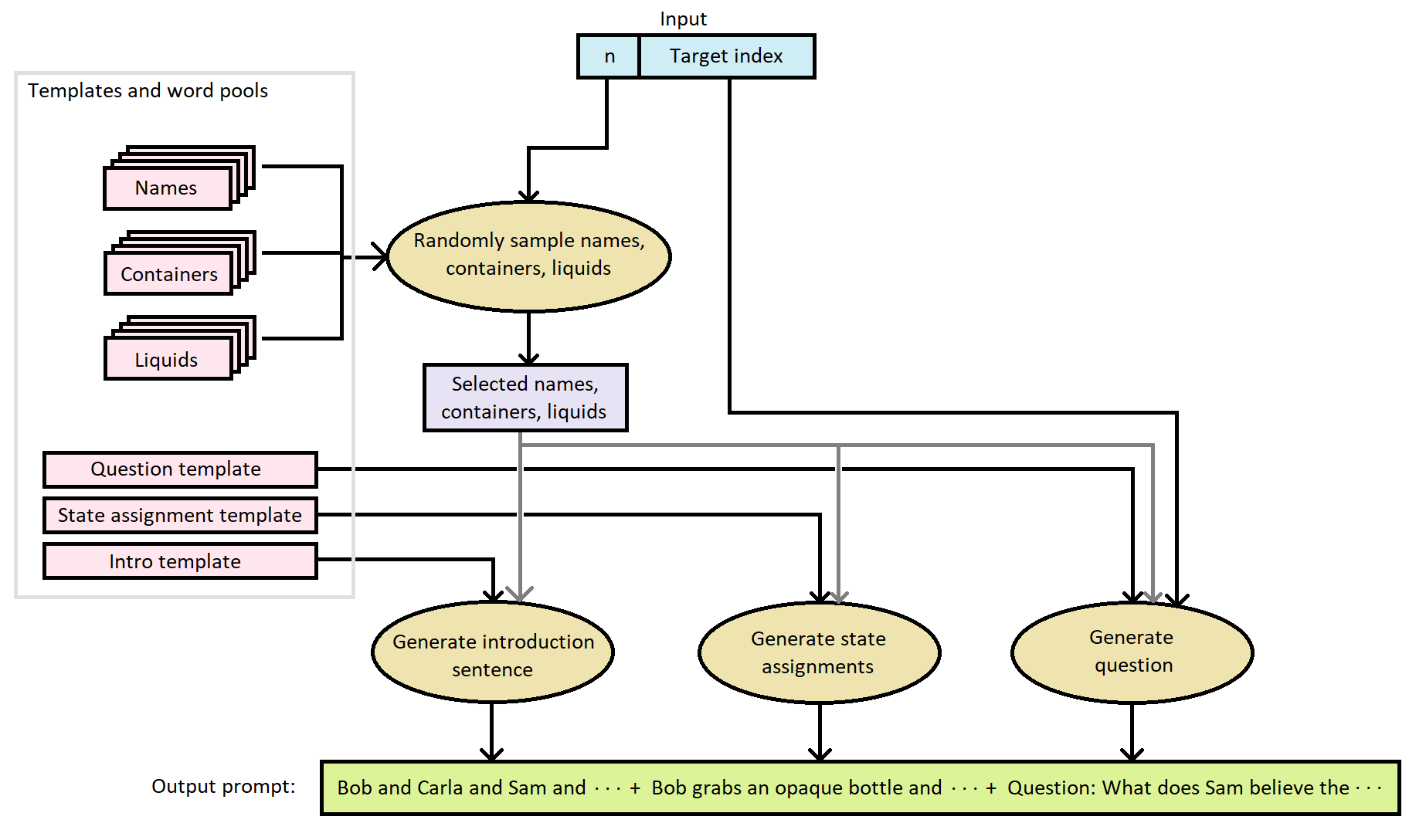
For some experiments, pairs of prompts are required which differ only in the order of introduction, order of state assignment sentences, and liquids. The generator handles this by simply regenerating a prompt with different randomly sampled liquids, and a different permutation of the introduction and state assignment order, while keeping the question sentence identical. Also, in many of the following experiments, random padding was added before and within the prompts to break the correlation between OIs and positional encoding.
Finding the OI in name tokens
Linear probes
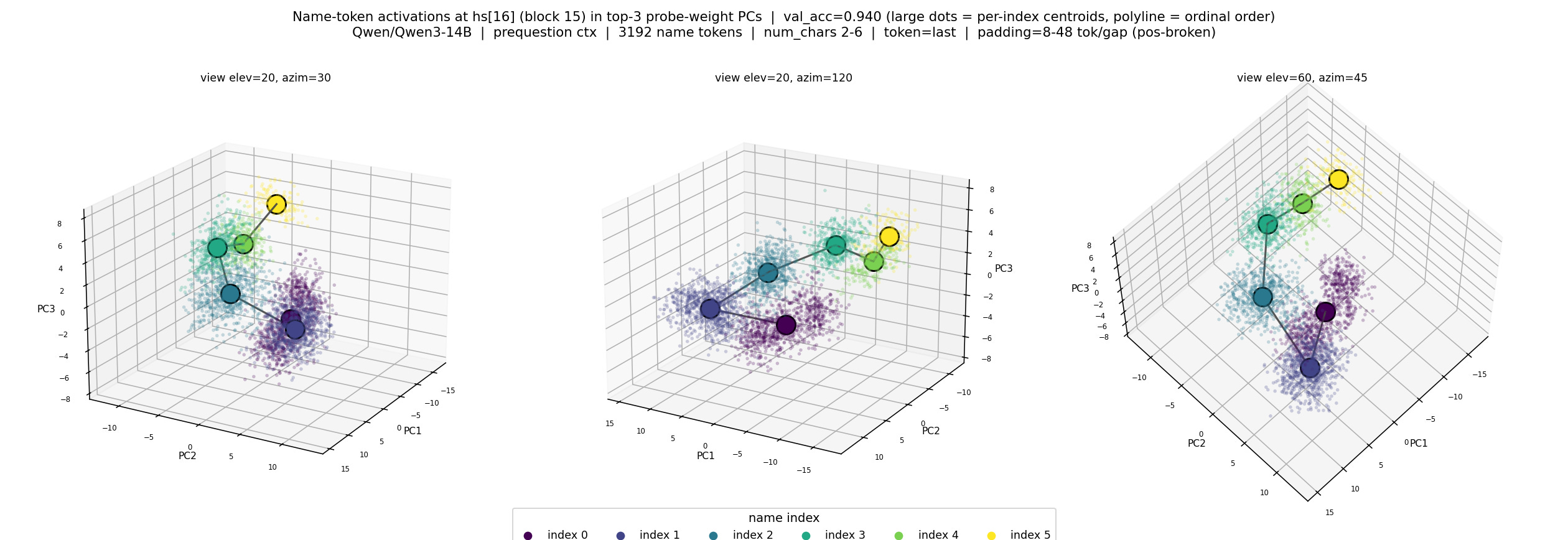
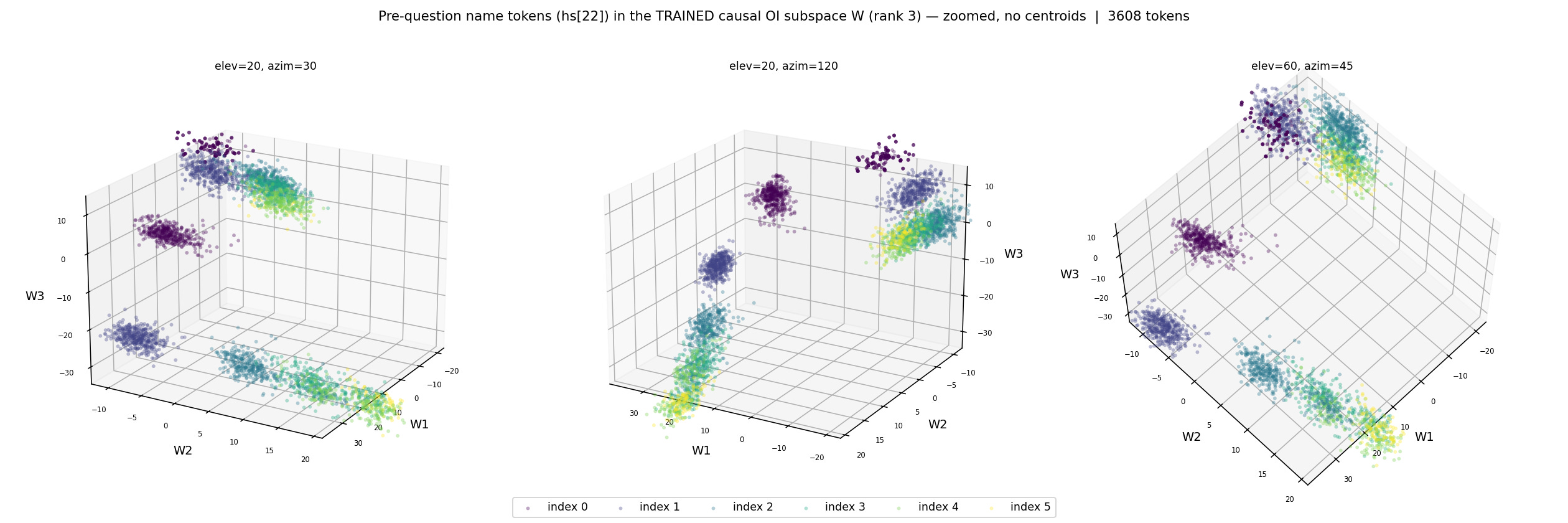
While Prakash et al exposes that OIs are used in this particular style of prompt, they only swap either the whole residual stream, or a relatively high rank subspace (<=20), and don’t investigate the shape of the actual representation. In search for this representation, I train a set of linear probes on the name tokens that appear before the question, to extract the index of that individual. The probes perform well, recovering the index with 98% accuracy. I then run PCA on the weights of these probes, and take the top 3 PC’s as the basis for a subspace where the representation presumably lives. Below, I create a scatter plot, seen in figure 4, by projecting activations into this subspace and color coding them by index, showing linearly separable clusters and a curved manifold.
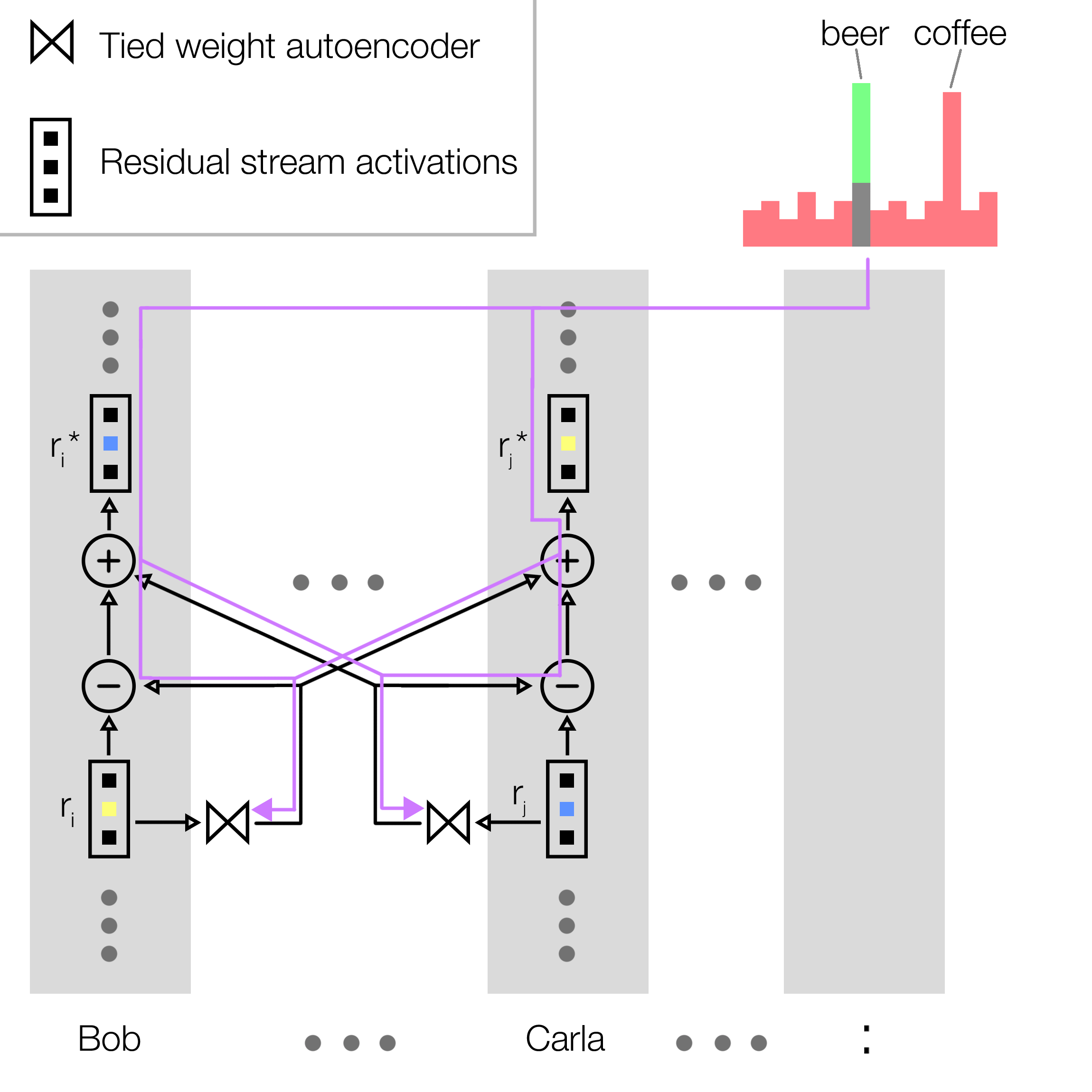
Next, I do a causal intervention to test how causally relevant this 3D subspace is to the task. To understand where the best place to do the swap is, we first need to understand the flow of information as hypothesized by Prakash et al. Figure 5 is a modified diagram from their paper, showing the OIs, stored in the colon token, being used as pointers to retrieve information from the correct state token. If the character OI flows from the name tokens (”Bob” and “Carla”) to the state tokens (”beer” and “coffee”), and that these OIs let the model look back to the right token, then swapping the OIs of the name tokens in the right layer should alter the models answer to the prompt. Based on the flow of information highlighted in figure 5, the swap needs to be done before the OIs are transferred to the state tokens, and after they are transferred to the tokens in the question. This should result in the pointer in the colon token dereferencing the incorrect state, i.e. the “beer” token instead of the “coffee” token. The red intervention zone in figure 5 highlights this region where I expect an intervention to work.
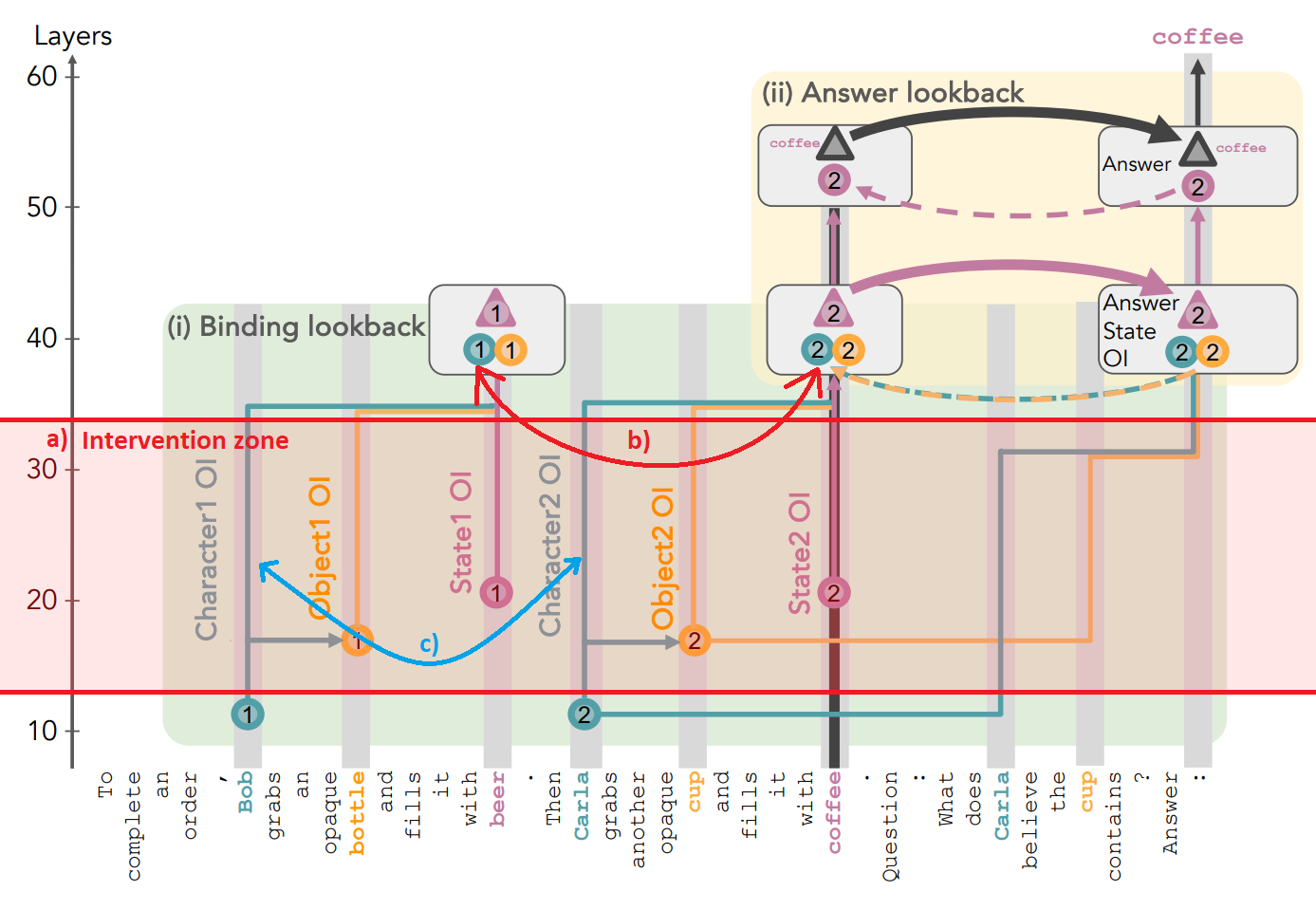

I swap the subspace spanned by the top 3 PC of the probe weight space, between the 2 different name tokens, as shown in figure 6. The first part of implementing the swap, is to run the full prompt through the model, up to a specified layer in the intervention zone, allowing the correct OIs to propagate to the colon token, but stopping before they are copied to the state tokens. Then, I perform the swap, only swapping the information in the identified subspace. I then allow the model to process the remaining layers and check if the answer swaps to the other state (”beer” instead of “coffee”, in the context of the figure 6 prompt). If the probes can identify the correct subspace where the OIs live, then we would expect there to be a swap in the output. While the probes were able to decode the index 98% of the time, and when visualized the subspace contains a clean manifold corresponding to index, the intervention did not change the output of the network at all, on any of the layers tested.
Using backpropagation to find a causally relevant subspace
Prakash et al’s results indicate that in some form or another, the causally relevant OI information must exist in these name tokens, therefore my hypothesis is that probes were finding an alternative but not causally relevant subspace. If this is the case, how can we find the correct subspace? If the criteria of success is finding a subspace that, across many different prompts of the same structure, swapping it between the name tokens results in a specific output logits change, then maybe we could directly optimize for success on this condition. While solving this analytically seemed infeasible, maybe gradient descent could be used to find this subspace. What I needed was a mechanism that swaps a low rank subspace between 2 different residual stream locations, where the specification of the subspace is learnable via gradient descent. A tied weight autoencoder is a good candidate for this, because it is a learnable bottleneck that necessarily extracts only a subspace, with no distortion, with as many dimensions as it has hidden neurons.
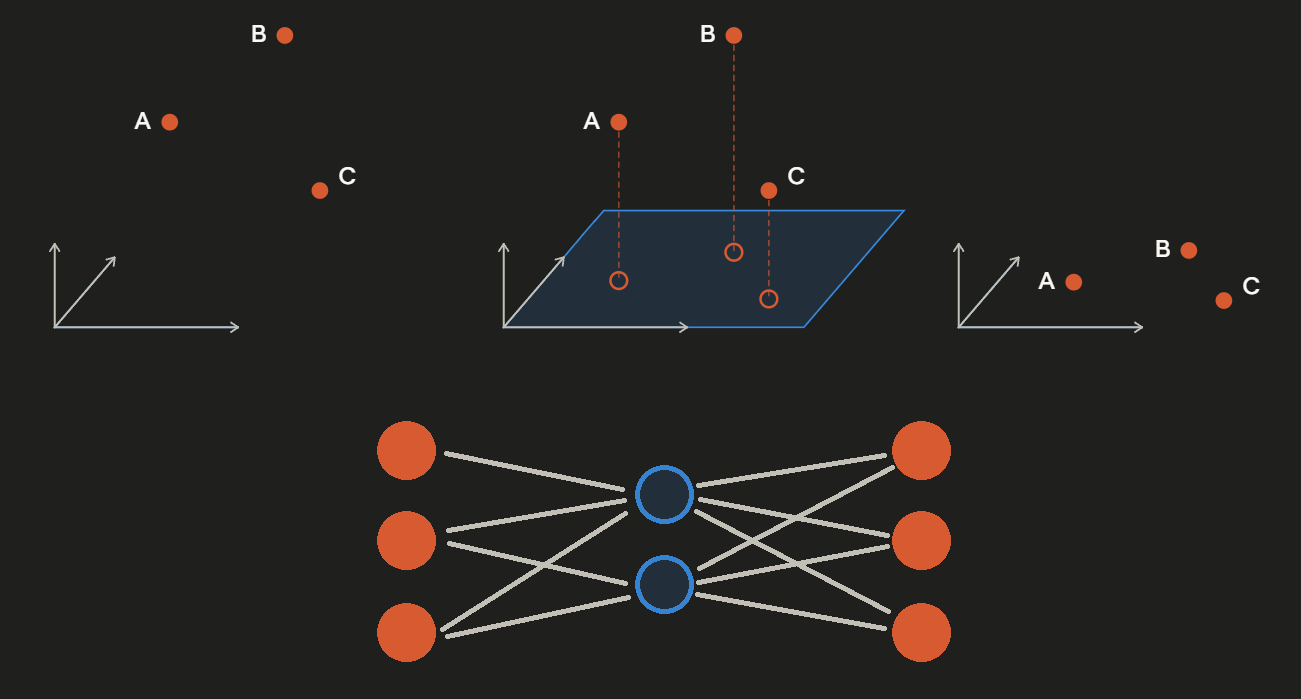
The training setup is similar to the evaluation of the probe subspace swap experiment; The prompt is run through the network up to a specified layer, but instead of swapping a pre specified subspace in the residual streams, the tied autoencoder runs on residual streams of the tokens that I wish to perform the swap on, and then the subspace isolated by the encoder is swapped between these tokens. The model then processes the remaining layers to produce the output logits. Since all operations up to this point are differentiable including the swap and autoencoder, I can then backpropagate from the output logits all the way back to the autoencoder’s tied weights.
To perform the swap in a differentiable way, at the swap tokens, I first run the residual stream through the autoencoder, then subtract the projected output from the original activations to clear the subspace. Next, the outputs from the autoencoder, from the other token, are added to the resulting residual stream, filling in that empty subspace with the information from the other token. This is done for both tokens, for all pairs of tokens to be swapped. This turns the swap into simple subtractions and additions, which gradients flow through smoothly. Equations 1 and 2 below show how the swap is computed, in terms of the residual stream vectors of both swap tokens i and j, and the weights of the autoencoder W.
1: ri* = ri - (ri WT)W + (rj WT)W
2: rj* = rj - (rj WT)W + (ri WT)W
equations 1 and 2: The swap, performed in a differentiable way on tokens i and j, where ri is the residual stream vector of token i before the swap, and ri* is the residual stream after the swap. W is the weights of the autoencoder, which uses tied weights and is run twice for every swap.
The loss function is cross entropy of the models final token against character B’s liquid, where character A is who the question asks about, and character B is who A’s activations are swapped with. For example, for the prompt in figure 6, the loss function pushes down the “coffee” logit, and pushes up the “beer” logit. I batch this over 192 randomized versions of the prompt to ensure generalization, invariant to the names used, the relative positions and orders of characters, and the names of containers and liquids used. After training this tied autoencoder with a hidden dimension of 3, I performed the same experiment I used to test the probe subspace, on the held out set of 64 prompts, and found it to flip the answer 86% of the time. I then plotted activations in this found subspace, as seen in figure 9 below.
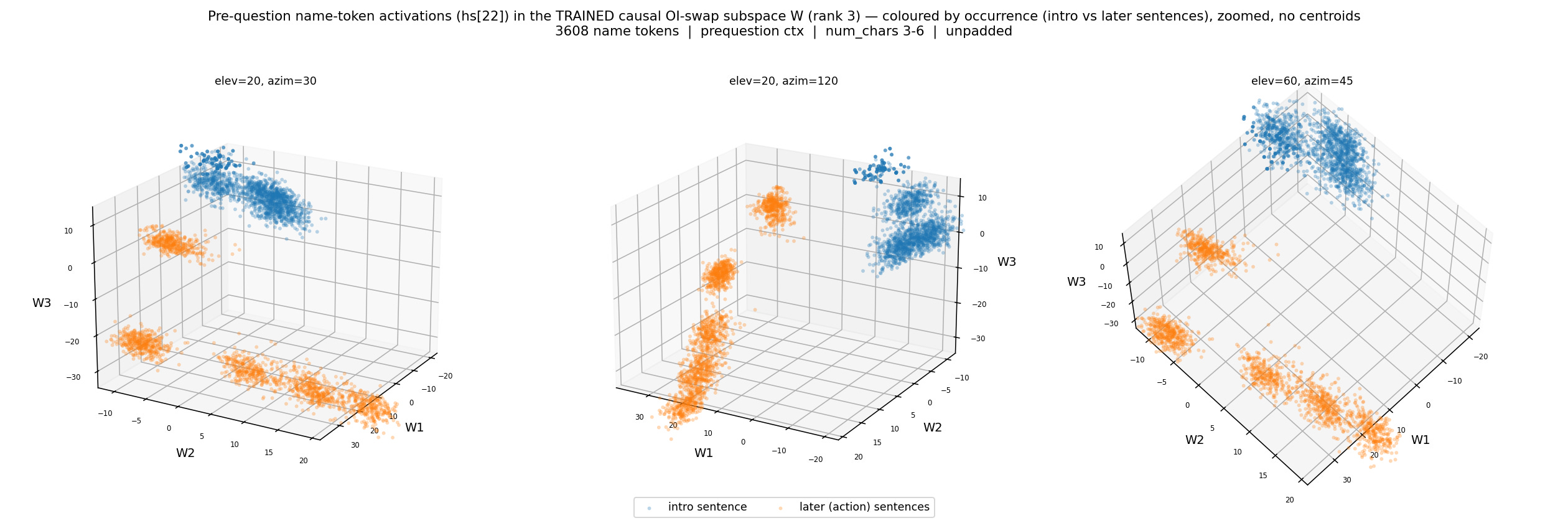
Interestingly, there appear to be 2 different groups of clusters in this subspace, one where the index clusters are arranged in a linearly separable way, where we can see a clear L shaped manifold, and another, which is less linearly separable. When color coded based on which part of the prompt the activations came from, shown in figure 10, blue corresponding to the introduction sentence, and orange corresponding to the state assignment sentences, we see that the less separable group corresponds to the introduction sentence only. Given this, it makes sense to assume it’s the orange set that is the real representation we are looking for, though further experiments could be done to verify this.
These results show a clear example of linear probes finding a clear representation in the residual stream, that is not causal, while the gradient descent based method finds a different, cleaner, representation that is causally relevant.
After some searching through the literature I found this technique has a name; Distributed Alignment Search (DAS), first introduced in Geiger et al 2024. While the implementation of their technique is not identical to mine and wasn’t applied to an LLM, they also use gradient descent to select a subspace to patch to achieve a desired change in behavior, in order to recover representations that other methods fail to find.
Finding the pointer representation in the “:” token
The method and results described so far are only with respect to intervening on the name tokens that come before the question, but I also wanted to investigate the representation of OIs in the final colon token (the existence of which is shown in Prakash et al, and is visible in figure 5), where they are used as pointers. Similar to my process for finding the representations present in the name tokens, I first tried training linear probes to recover the index of the individual mentioned in the question, in the residual stream of the final colon token. Similar to the earlier probe training, the probes performed well at predicting the index, with an accuracy of 98%. In contrast to the earlier probe results however, plotting these activations gives us a less coherent manifold, where the clusters appear less linearly separable in the first 3 PCs. The lack of linear separability here indicates the probes rely on much more than just these top 3 directions for making predictions, given their high performance.
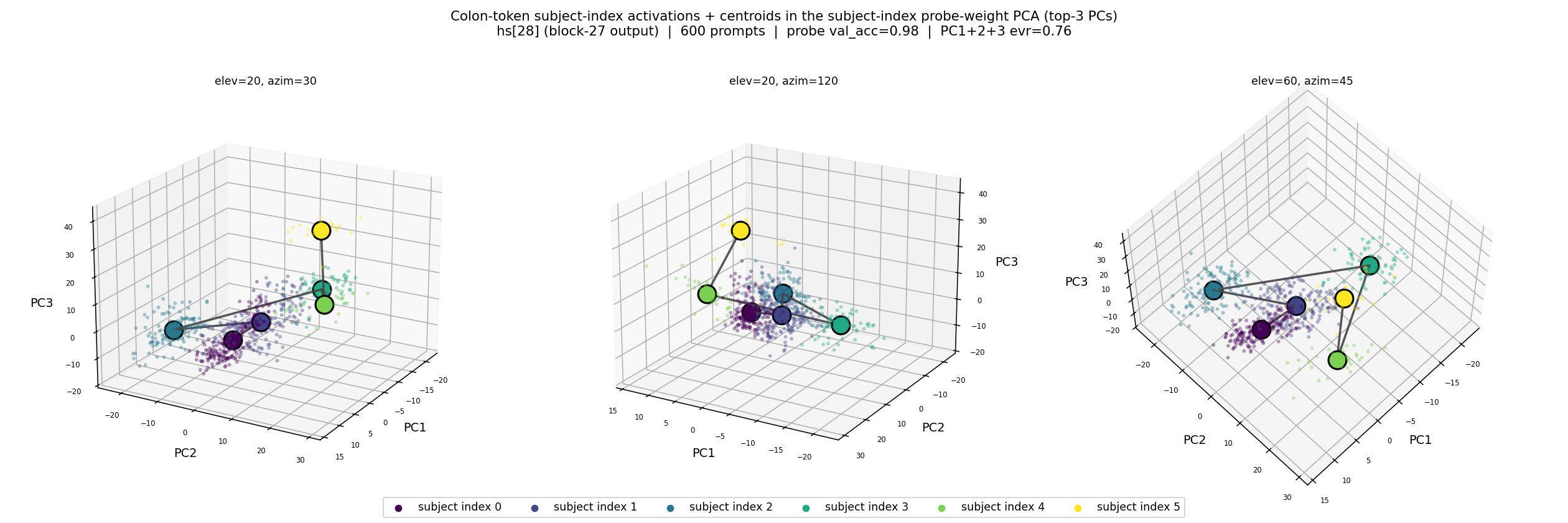
Next, similar to the previous probe experiment, I do a causal intervention through activation patching to test how causally relevant the found subspace is. My method here is similar to Prakash et al, where I have a recipient and donor prompt, and patch the subspace from the donor into the recipient, and measure what percentage of the time the output flips to the target character in the recipient prompt. In this experiment, I call the index of the individual who the question is about, in the donor prompt, the “target index”, and in the recipient prompt, the “query index”. The goal of this intervention, is to demonstrate the same result as Prakash et al, where the activation patching flips the models answer from the state corresponding to query index, to that of the target index. This causal intervention, done by swapping the top 3 PCs of the probe subspace, succeeded with a flip rate of 60%. While 60% may sound reasonable, when we break down the result by target index, we see that the success of the intervention is mostly concentrated in cases where the target index is the first or second.

Due to the poor results of this probe based intervention, I decided to again take a gradient based approach to finding the causal representation. The method I used here is similar to the swapping approach detailed earlier, but this time instead of swapping between the residual streams of 2 different tokens in the same prompt, I train the tied weight autoencoder to extract the subspace from the colon token of the donor prompt, and copy it to the recipient prompt; the same setup used to test the causal relevance of the probe found subspace.
After training, causal interventions using the 3D subspace found by the autoencoder were 88% successful, with the accuracy more evenly spread across slots too, as seen in table 2.

Now that we have found a causally relevant subspace which contains the representation of OIs that the model actually uses as pointers, I create a scatter plot, by collecting activations from layer 27 (where we found the representation) and then projecting them into top 2 and 3 PCs of the subspace found by DAS.
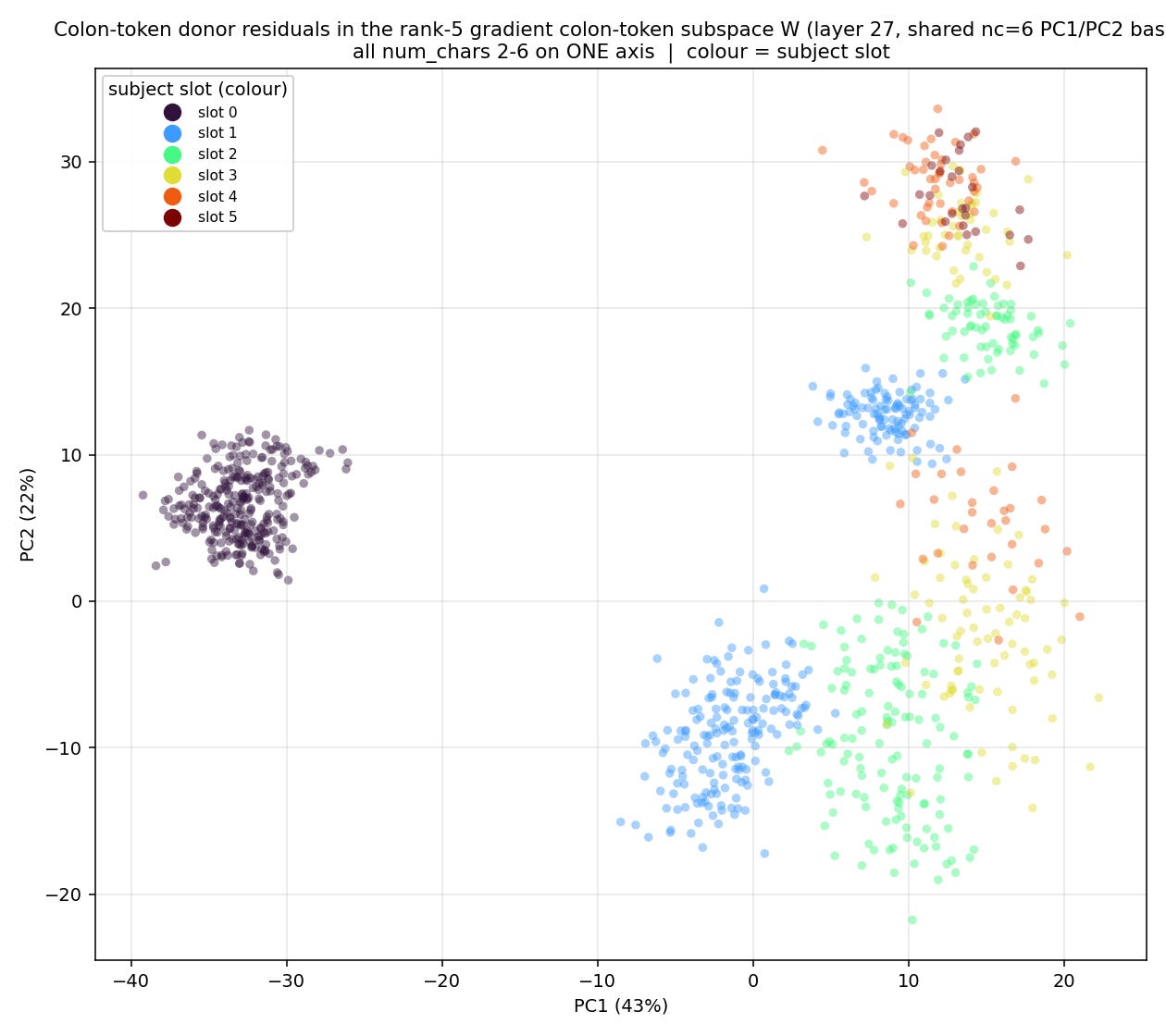
This is not exactly what I was expecting to find, these clusters are not linearly separable, and it’s strange that there are multiple tight clusters per slot. When we separate the clusters based on the number of unique names in the prompt however, we get this:
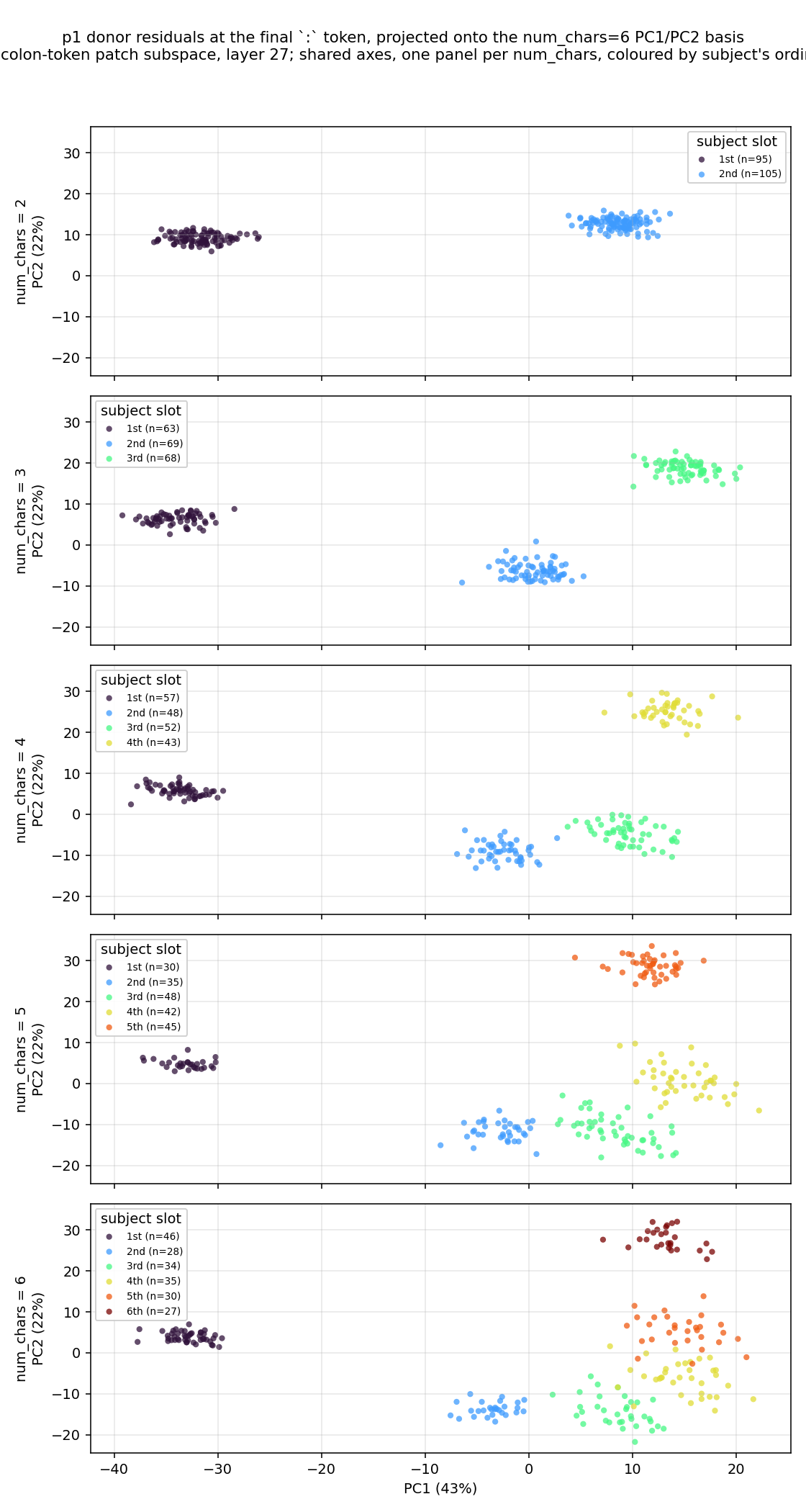
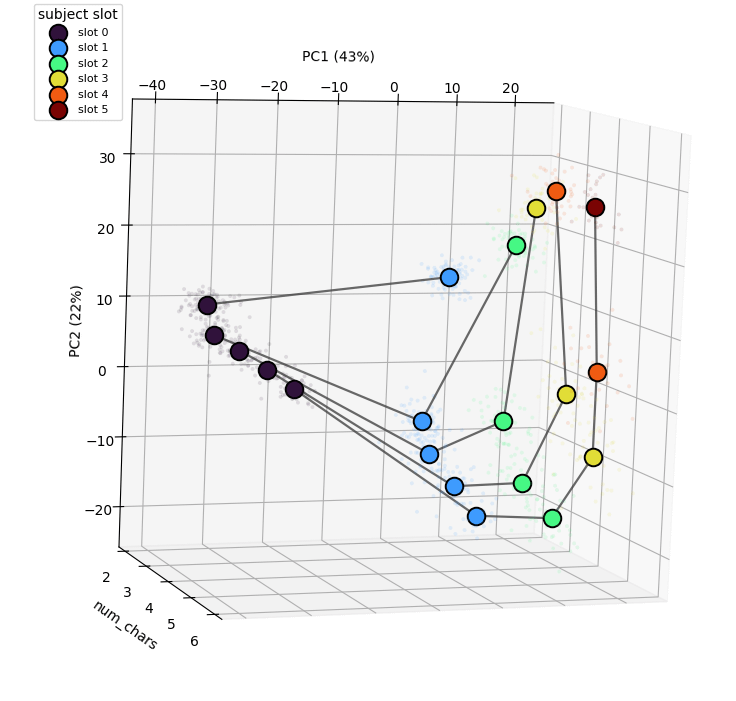
Separated like this, it’s clear; for each number of names, there is a clean representation of index along a manifold. The interesting part is that it is a parametric manifold: the shape of the manifold changes based on some other information, in this case the total number of individuals in the prompt. This parametric property explains why the linear probes could not recover this subspace, since, to a linear probe, linear separability is necessary for prediction, while for the gradient based method, the only criteria is causal relevance. The manifold, plotted for each number of names used, is plotted below in figure 14. It’s important to note that while it’s possible to find a projection of this 3D shape that gives us linearly separabilty, it is only because we have artificially added a num_chars dimension.
Limitations:
Currently I am treating these results as preliminary, because many of them need to be verified more thoroughly, and there are open questions relating to the conclusions I’ve taken from them. One important question is: is the parametric manifold real? It’s easy to be incorrect here, if for example the subspace I found contains part of another representation influenced by the number of unique names, which distorts the shape in a way that makes it appear parametric. To combat this I spent some time trying to find a way to project these clusters in ways that are linearly separable in a small number of dimensions, but I had no luck. This is also reinforced by the fact that the probes also couldn’t find this, but further investigation is needed. Generality of the findings also needs to be investigated; while my dataset generation covers a much wider space than that of Prakash et al, it needs to be investigated whether these findings translate to different kinds of tasks, and importantly, different models.
Final thoughts:
With this project, I initally set out to to use methods I was already comfortable using, linear probes, to find a representation that I was curious about. The early failures of this project show the limitations of linear probes and the deceptiveness of results gathered from them, while the later successes show the strengths of DAS as a technique for uncovering causally relevant representations. While there is still a lot of work to do to better verify the results in this post, they make me optimistic about DAS as an approach.
References:
Prakash, N., Shapira, N., Sen Sharma, A., Riedl, C., Belinkov, Y., Rott Shaham, T., Bau, D., & Geiger, A. (2025). Language models use lookbacks to track beliefs. arXiv:2505.14685. arXiv
Feng, J., & Steinhardt, J. (2023). How do language models bind entities in context? arXiv:2310.17191. arXiv
Dai, Q., Heinzerling, B., & Inui, K. (2024). Representational analysis of binding in language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17468–17493, Miami, Florida, USA. Association for Computational Linguistics. arXiv:2409.05448. ACL Anthology
Geiger, A., Wu, Z., Potts, C., Icard, T., & Goodman, N. D. (2023). Finding alignments between interpretable causal variables and distributed neural representations. arXiv:2303.02536. arXiv